





深入解析360智脑RAG方案:SuperCLUE-RAG榜单夺冠背后的技术洞察
引言

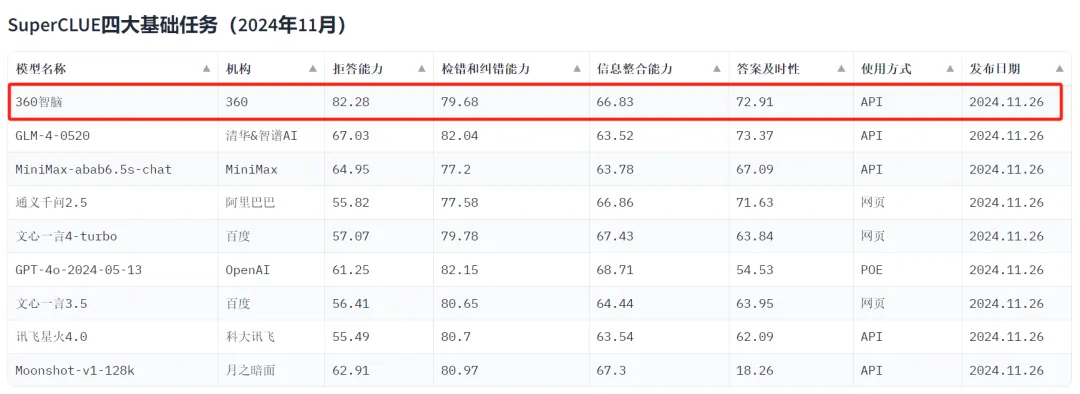
为什么大家这么关注RAG技术?
在大模型(LLM)落地过程中,存在诸多挑战,如缺乏企业私有知识存在幻觉问题、训练周期长成本高、知识更新不及时的问题以及模型的黑箱属性缺乏可解释性的问题等。而RAG(Retrieval-Augmented Generation,检索增强生成)技术的引入,可以有效地解决这些问题。
LLM缺乏企业的私有知识,存在严重幻觉问题。大模型通常基于互联网公开数据进行训练,难以涵盖企业的私有知识。RAG技术通过构建企业私有知识库,实现私有知识注入,使得模型能够更好地服务于企业的具体需求。 LLM训练周期长成本高,存在知识更新不及时。大模型的训练周期长且成本高,更新知识需要耗费大量资源。通过迭代管理知识库内容,RAG技术能够实现知识的快速更新,而无需重新训练整个大模型,从而大大降低了成本和时间。 LLM属于黑箱模型,缺乏可解释性。大模型的黑箱属性使其回答缺乏可解释性。RAG技术可以显示答案的引用文档信息,提高了回答的透明度和可解释性,让用户可以追溯答案信息的来源,增强了模型的可信度。
检索器(Retriever)。负责从预定义的文档集合中检索与输入查询相关的文档或片段。 生成器(Generator)。利用检索到的文档或片段作为上下文,生成连贯且与查询相关的回答。
数字员工。RAG 技术可以用于开发智能数字员工,这些数字员工能够理解并处理复杂的任务。例如,在客服领域,RAG 可以帮助数字员工快速检索相关信息并生成准确的回答,从而提高客户满意度和工作效率。 辅助决策。在商业决策过程中,RAG 技术可以帮助管理人员快速获取相关数据和信息,并生成有价值的见解。例如,在市场分析中,RAG 可以从大量的市场数据中提取关键信息,并生成分析报告,帮助企业做出明智的决策。 知识管理。RAG 技术在知识管理中也有广泛的应用。它可以帮助企业构建智能知识库,通过检索和生成技术,快速找到并提供所需的信息。例如,在技术支持和培训中,RAG 可以帮助员工快速获取技术文档和操作指南,提高工作效率。 内容创作。内容创作是 RAG 技术的另一个重要应用场景。RAG 可以帮助创作者生成高质量的内容,如文章、报告、广告文案等。例如,在新闻报道中,RAG 可以从多个信息源中提取关键事实,并生成连贯的新闻稿,为读者提供及时、准确的信息。
拒答能力:模型是否能够在无效或无答案的情况下,准确地拒绝回答。 检错与纠错能力:包括对错误信息的识别准确性以及修正后的文本正确性。 信息整合能力:考察模型在多文档场景下,如何提炼关键信息并生成准确、规整的回答。 答案及时性:评估模型回答的准确性与清晰度是否能够满足快速响应的要求。
拒答案例:针对提问知识库中未覆盖的知识点场景,360智脑RAG能明确拒答,有效避免模型生成幻觉。

图3:2024年11月份SuperCLUE-RAG评估中拒答维度案例检错与纠错能力:针对问题与知识库内容不一致的场景,能准确根据外挂知识帮助用户进行纠错

图4:2024年11月份SuperCLUE-RAG评估中检错与纠错维度案例信息整合能力:针对复杂查询场景,能全面召回跨文档的相关信息并准确整理进行回答。

图5:2024年11月份SuperCLUE-RAG评估中信息整合维度案例答案时效性:针对询问时效性信息场景,能及时联网查询获取最相关答案

360智脑RAG方案

首先,文档解析能够有效地提取和理解文档中的关键信息,从而为后续的信息检索和生成提供准确的基础。 其次,通过对文档的深入解析,可以更好地捕捉上下文关系,使得生成的内容更加连贯和符合逻辑。 此外,精确的文档解析还能够帮助识别和过滤噪音信息,确保检索到的内容具有高质量和高相关性。 总之,文档解析是RAG过程中不可或缺的一环,它直接影响到信息检索的效率和生成内容的质量。
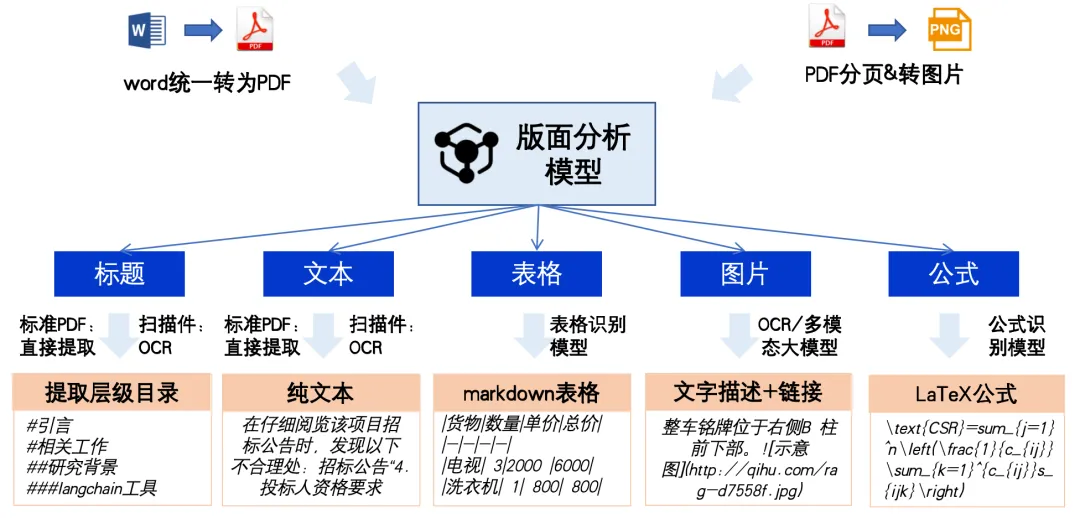
第一步,文档统一会被转换成PDF格式。 第二步,PDF文件会被分割并按页渲染成图像,以便后续的图像处理和分析。 第三步,我们会使用版面分析模型来识别文档中的各种元素,如标题、正文、表格、图片、图表和公式等。 第四步,不同的元素再用不同的模型识别处理,如标题和文本用OCR模型识别;表格用表格模型识别还原数据;公式用公式模型识别出latex公式。 最后一步,这些识别出的元素会按照阅读顺序进行排序,并输出为markdown格式,以便于进一步编辑和使用。通过这些步骤,我们能够高效地解析和处理各种复杂的文档。
第一点,chunking可以将大段文本拆分成更小的、易于管理的块,从而提高信息检索的效率。通过合理的chunking,可以确保每个块包含足够的信息,使得生成模型能够更准确地理解和生成相关内容。 第二点,chunking有助于减少噪音和冗余信息的干扰,使检索结果更加精确和相关。 第三点,适当的chunking还可以优化计算资源的利用,减少处理时间和内存消耗。因此,chunking方式在RAG过程中不仅影响信息检索的质量,还直接关系到整个系统的性能和效率。
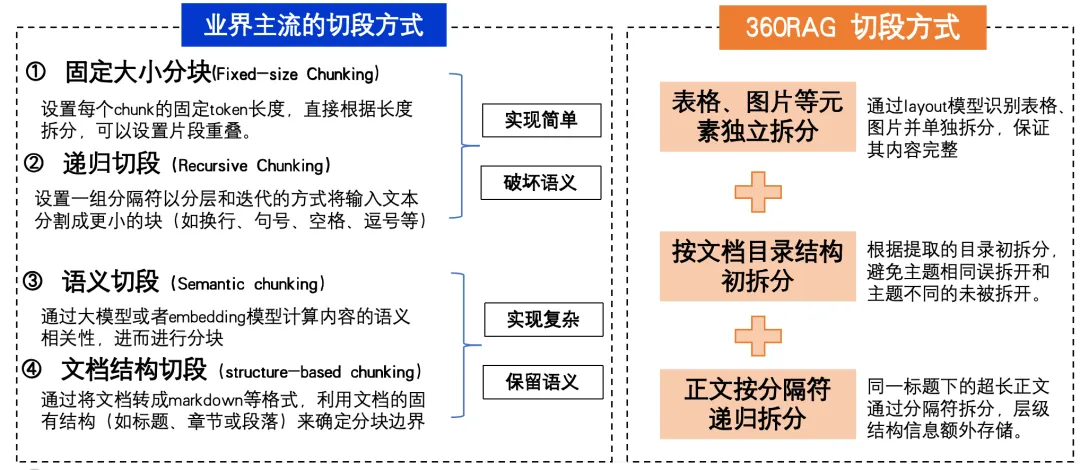
生成QA对。通过根据内容生成QA对,可以丰富数据的语义信息,使得模型在回答问题时更加准确。 生成摘要。对片段做摘要总结,有助于提取关键信息,提高检索效率和准确性。 添加元数据。提取日期、页码等元数据,可以为检索提供更多维度的信息,方便用户快速找到所需内容。 构建知识图谱。提取实体和关系并构建知识图谱,能够将数据中的隐含关系显性化,增强模型的理解能力,从而提升整体检索效果。
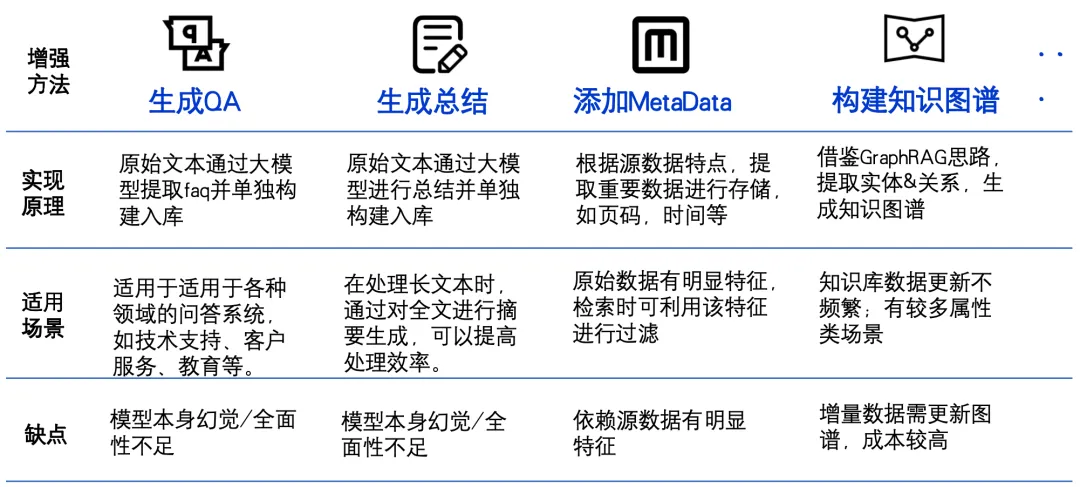
首先,query纠错、指代消歧和query改写能够帮助系统更好地理解用户的意图,通过将原始查询转换为更易于处理的形式,提高检索效果。 其次,泛化子查询可以扩展查询范围,确保涵盖更多潜在的相关信息。query意图判定则是通过分析用户查询背后的真实需求,进一步优化检索结果。 最后,回溯提示功能允许系统先考虑层次的概念和原则以解决复杂问题。这些查询策略的综合应用,能够显著提升RAG系统的性能和用户满意度。

通过chunk召回相关片段。将原始文章分成多个小块(chunk),每个小块包含一定数量的句子或段落。检索阶段可以有效地找到与当前内容相关的上下文信息。 通过文章的篇章标题结构确定上下文边界。在扩展上下文时,考虑文章的整体结构,特别是篇章标题。这有助于确定各部分内容的主题和边界。确保召回的片段与当前段落所在的章节或小节内容一致,从而保持上下文的连贯性和逻辑性。 通过NLP技术过滤掉无关噪声片段。采用技术如:1) NLI模型过滤,通过训练独立的NLI模型对召回结果进行语义相似性判断,保证性能的同时可有效过滤无关内容;2)实体识别过滤,通过提取query和召回question里的实体,维护实体+别名库,可实现别名的召回以及关键实体缺失的过滤;3) 规则引擎过滤,实际应用中总有一些corner case覆盖不到,通过规则引擎运营自定义规则,来实现干预处理,常见的规则,如完全精确匹配、包含匹配、正则匹配、模糊匹配(语义匹配)。
第一,进行查询预处理是整个过程的基础,通过对查询进行优化和标准化,可以提高检索的准确性和效率。 第二,任务规划是关键步骤,它决定了如何有效地组织和调度检索任务,以确保高效利用资源。 第三,在生成初步结果后,反思阶段尤为重要,通过对生成内容进行审查和评估,可以发现潜在的问题和改进点。

总结
文档解析的质量决定了RAG能力的上限。 细粒度、语义级、边界精确的文档切片对RAG至关重要。 针对文档内容的多样化数据增强策略是一种有效的提升RAG效果的方案。 准确的query理解和任务规划策略对于RAG召回至关重要。 精确、丰富、完备、不含噪声的上下文信息对大模型是友好的。 用好慢思考能力,推理和反思能够帮助RAG提升能力上限。
-
本文分类: 行业资讯
-
本文标签:
-
浏览次数: 2245 次浏览
-
发布日期: 2024-12-20 17:45:23



热门推荐












 京公网安备 11000002002063号
京公网安备 11000002002063号  电话咨询
电话咨询
